딥러닝 개요
신경회로망(Neural Network)
💠인간의 두뇌 작용을 신경 세포들 간의 연결관계로 모델링
💠 뉴런 및 뉴런 간의 연결 구조를 모방
- 뉴런 - 시냅스에 연결된 뉴런들의 전기 신호의 합이 역치 이상이면 다음 뉴런으로 신호 전달
- 신경회로망 - 입력 값들의 가중합이 문턱치 이상이면 다음 계층으로 신호 전달

단층 퍼셉트론(Perceptron)
💠 1957년 F.Rosenblatt이 뉴런 모델을 기초로 제안
💠각 입력 값에 가중치를 부여한 결과를 합침
💠활성 함수를 도입
- 임계 값 이상의 값만 통과
💠예측 값과 실제 출력의 차이를 통해 가중치들을 갱신하여 학습

단층 퍼셉트론을 통한 AND 문제 해결
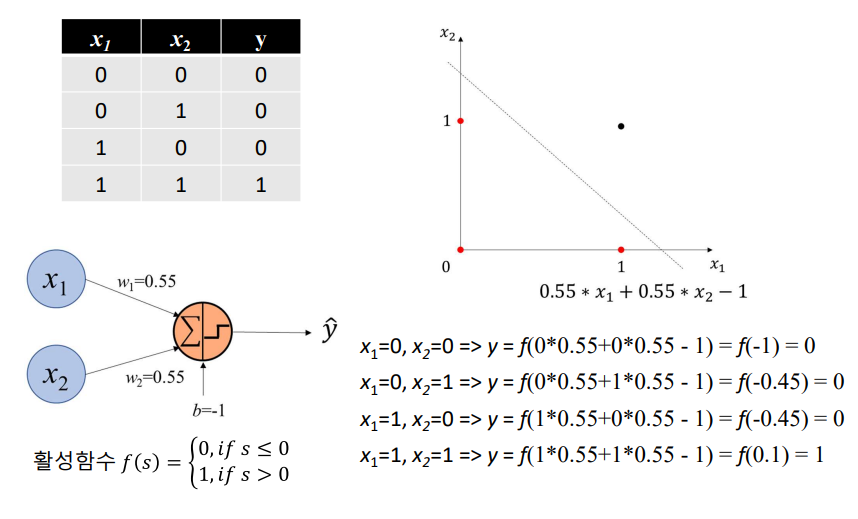
단층 퍼셉트론을 통한 XOR 문제 해결 불가능
💠단층 퍼셉트론은 비선형 문제를 해결할 수 없음

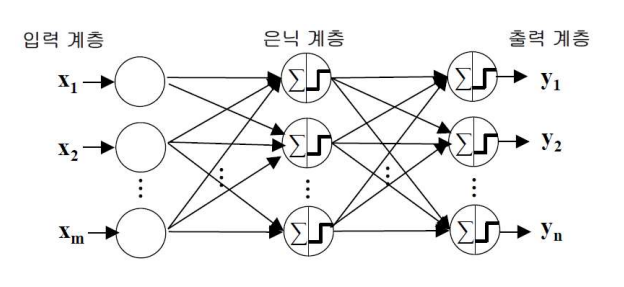
다층 퍼셉트론(Multilayer Perceptron)
💠입력계층, 출력계층과 함께 하나 이상의 은닉(hidden) 계층으로 구성된 퍼셉트론
💠1986년 D.E.Rumerhart등이 제안
💠역전파(backpropagation) 학습 알로리즘을 통해 효율적인 가중치 학습
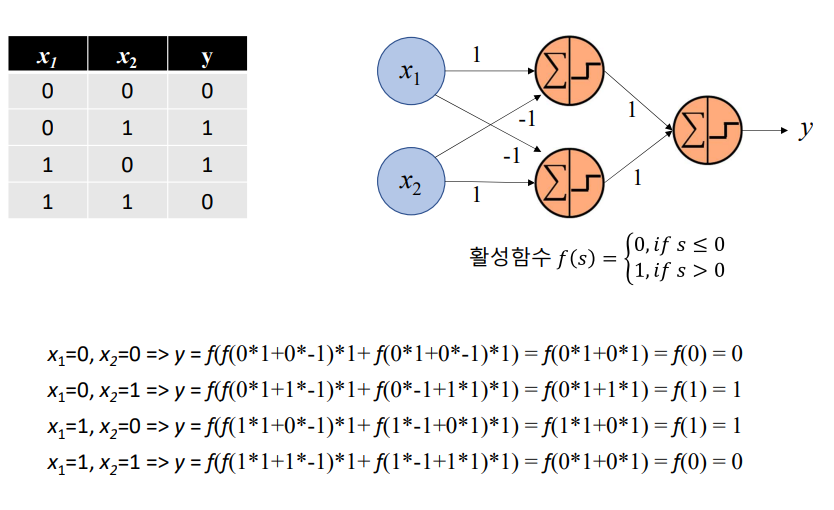
💠XOR 문제뿐만 아니라 다양한 활성화/손실 함수를 통해 비선형 분류, 회귀 등 여러 문제를 해결할 수 있음
다층 퍼셉트론을 통한 XOR 문제 해결
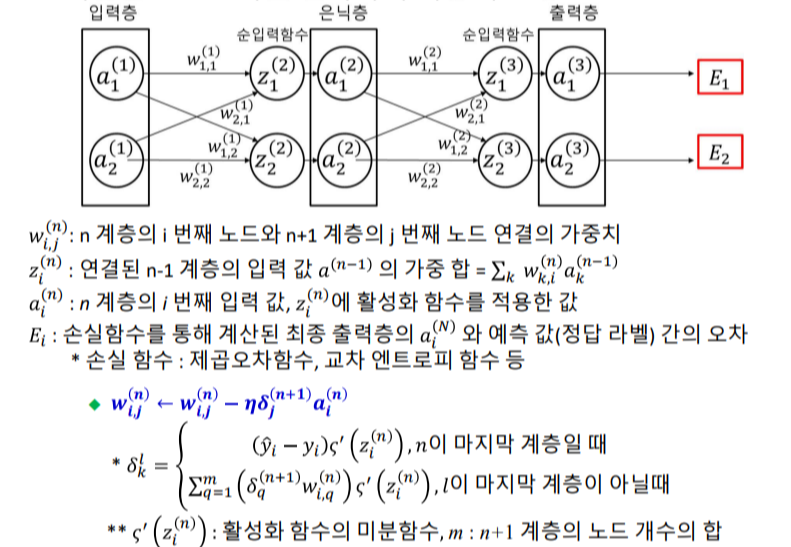
역전파 알고리즘
💠역방향으로 오차를 전파하여 가중치 보정
딥러닝 종류
💠신경망 계층 구성, 각 계층간 연결, 가중치 구성 등에 따라 분류
- DNN
- CNN
- ViT(Vision Transformer)
- U-Net
- VAE(Variational AutoEncoder)
- GAN
- Diffusion
1) DNN(Deep Neural Network)
💠입력층과 출력층 사이에 다수의 은닉층으로 이루어진 인공신경망
💠특징 추출이 자동으로 수행
💠CNN, RNN, LSTM 등의 신경망은 DNN을 응용

2) CNN(Convolution Neural Network) - 합성곱 신경망
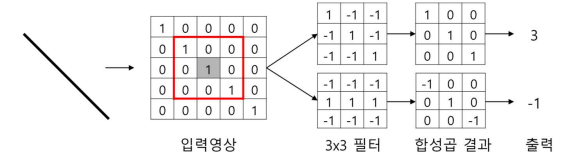
💠영상의 2차원 특징을 유지하는 신경망
💠DNN의 가중치를 대체하는 사각형 커널(필터) 도입
💠커널과 이전 단계의 특징 맵을 합성곱 연산하여 특징 맵 추출
💠최종 단계에서 1차원으로 변환하여 영역 검출, 분류 수행
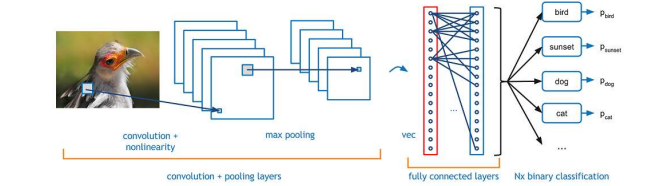
CNN의 이점
💠얕은 단계에서 경계선 등 국소적인 특성 추출
💠깊은 단계에서 사물의 형태 등 전체적인 특성 추출
💠실제 사람이 사물을 인식하는 방법과 유사

3) ViT(Vision Transformer)
💠자연어 처리에 활용되는 Transformer 구조를 영상에 적용한 것
💠입력 영상을 다수의 영역으로 분할한 후, 각 영역에서의 특징을 기존 CNN을 통해 추출
💠추출된 영상 특징을 단어의 특징으로 간주하여 처리

CNN과 ViT 비교
💠CNN
- 필터를 통한 합성곱으로 로컬 영상 정보를 잘 획득하지만 전역 정보 획득에는 한계가 있으며 많은 레이어가 필요
- 연산 속도가 빠름
- 특정 데이터셋에 과적합될 위험이 큼
💠ViT
- 다른 모든 영역과의 관계성을 직접 연산하기 때문에 전역 정보를 잘 획득할 수 있지만 로컬 영상 정보 획득은 상대적으로 약함
- 대량의 데이터셋이 있을 경우 성능이 뛰어남
- 다른 정보(텍스트, 소리 등)과의 결합이 용이함
- 연산속도가 느리고, 메모리 사용량이 많음
4) U-Net
영상 분할 모델
💠영상 내 객체를 화소 단위로 인식하는 모델
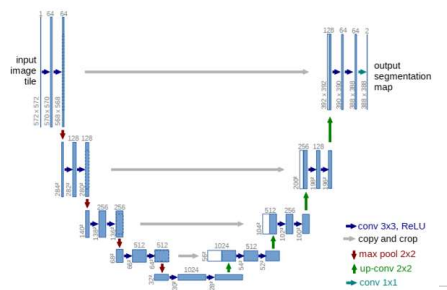
U-Net
💠적은 수의 학습 데이터로 영상 분할을 학습할 수 있는 모델
💠U자형 구조를 가지고 있음
- 축소경로(인코더) : 영상을 축소하면서 구간별로 특징을 검출
- 확장경로(디코더) : 특징 해상도를 확대하면서 같은 영상 크기에서 추출된 특징과 합침
- 축소 경로와 확장 경로가 서로 대칭
영상 생성 모델
💠 생성명 모델
- 원래의 데이터가 가지는 공통적인 특징을 학습하여 새로운 데이터를 생성하는 것
- 텍스트, 사운드, 영상 등 거의 모든 형태의 데이터 생성 가능
- 최근 인공지능의 핵심 기술 중 하나로 주목받고 있는 모델
💠 이미지 생성 모델
- 인공지능을 활용하여 새로운 이미지를 생성하는 모델
- 영상에서 나타나는 공통적인 특징을 학습하고, 이를 이용하여 새로운 영상을 생성함
- Autoencoder, GAN, Diffusion 등
5) VAE
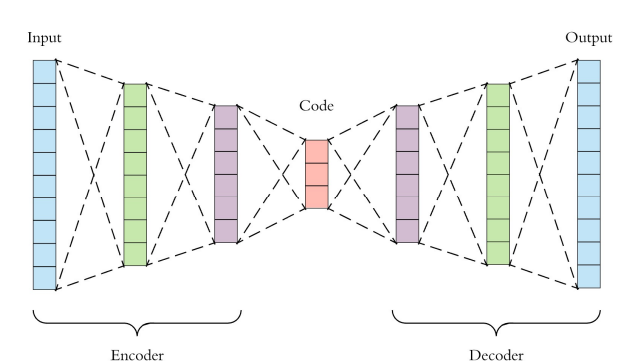
오토인코더
💠 인코더와 디코더 구조를 통해 이미지의 주요 특징을 추출하는 것을 학습하는 모델 구조
💠 입력 영상과 출력 영상을 동일하게 하는 것이 학습 목적
- 인코더 : 해상도를 축소하면서 영상의 주요 특징을 추출(손실압축)
- 디코더 : 특징을 확장하면서 원 영상으로 복원(압축을 복원하는 것)
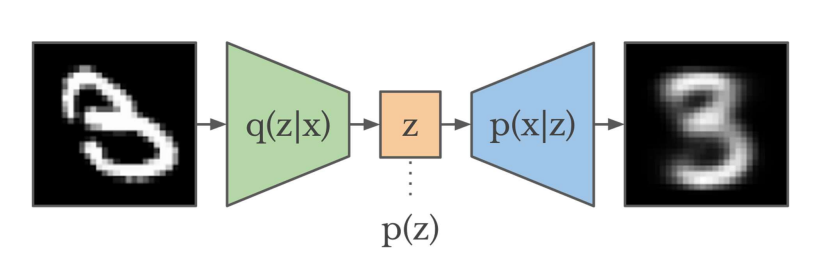
Variational AutoEncoder
💠 오토인코더와 유사한 구조이지만, 디코더를 통해 이미지를 복원(생성)하는 것을 학습하는 것이 주요 목적
- 오토인코더:인코더 학습을 통한 특징 추출에 중점을 둠
💠 학습 과정에서 인코더를 통해 찾은 영상의 특징에 잡음을 추가시켜서 이를 복원하도록 함
💠 임의의 잡음을 학습된 디코더에 입력하여 영상 생성
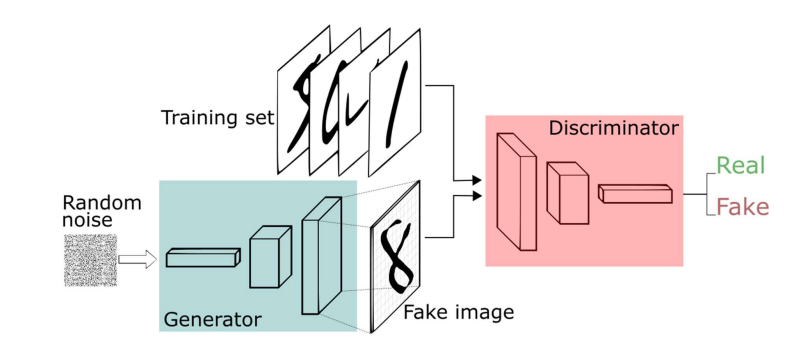
6) GAN(Generative Adversarial Network)
💠 적대적 생성 모델 - 생성자와 판별자가 적대적으로 경쟁
- 생성자 - 판별자를 속일 수 있는 데이터 생성
- 판별자 - 살제 데이터와 판별자가 생성한 데이터를 정확하게 분류
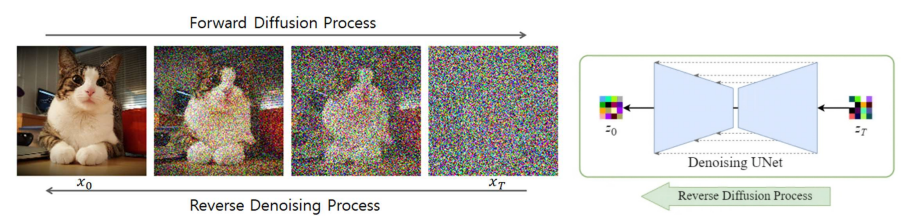
7) Diffusion
Diffusion 모델
💠 Diffusion 모델은 잡음을 제거하는 방법을 학습하여 잡음 이미지에서 영상을 생성함
- 이미지에서 단계적으로 무작위 잡음을 추가하면 최종적으로 완전한 잡음 이미지로 변환되고, 여기서 단계별로 잡음을 제거하면 원래 이미지로 복원할 수 있다는 것을 이용함
💠 잡음 제거 모델로 U-Net 사용함
- U-Net에서 영상 내 잡음을 검출하여 제거하는 것을 반복하여 영상생성
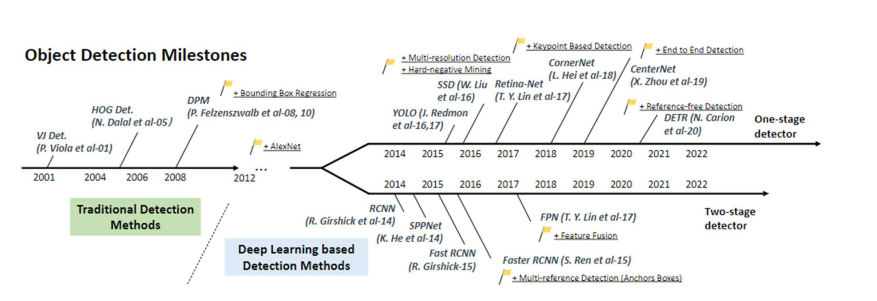
비전 기반 객체 인식
역사
💠 Krizhevsky의 Convolution layer 도입을 통한 개겣인식의 즉적인 개선
💠 CNN을 통한 객체 인식 연구가 활발하게 이루어지고 있음
- R-CNN, Fast R-CNN, Faster R-CNN, YOLO, DETR 등
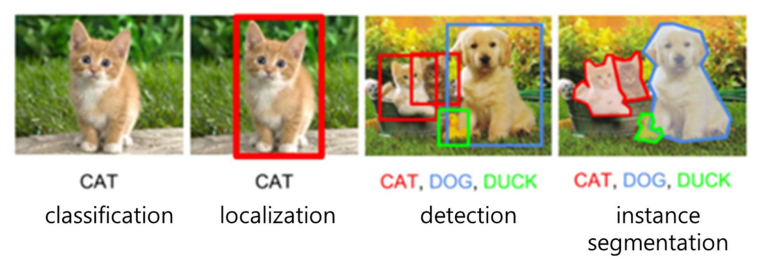
문제 정의
💠 검출하고자 하는 객체 갯수 및 검출하려는 정보에 따라 4가지로 분류
- classification : 단일 객체 분류
- localization : 단일 객체 바운딩 박스 검출
- detection : 다중 객체 분류 및 바운딩 박스 검출
- instance segmentation : 다중 객체 분륲 및 영역 검출
2-Stage Detector
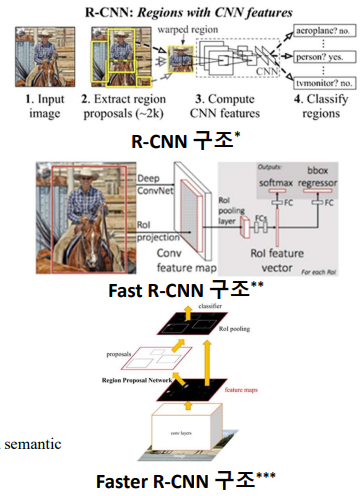
💠 객체 영역을 먼저 검출한 후, 객체분류
💠 R-CNN(Region-based CNN)
🔸영역 검출-특징 추출-객체 분류 수행
- selecttive search 알고리즘을 통행 영역검출
- CNN을 통해 특징 추출
- 선형 분류기를 통해 객체 분류
🔸속도가 매우 느림
💠 Fast R-CNN
🔸객체 분류를 CNN에 통합
💠 Faster R-CNN
🔸영역 검출도 CNN에 통합
💠 Mask R-CNN
🔸영역 검출 개선을 통한 정확도 향상
* R. Girshick et al., “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proc. CVPR, 2014. ** R. Girshick, “Fast R-CNN,” in Proc. ICCV, 2015. *** S. Ren et al., “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Proc. NIPS, 2015.
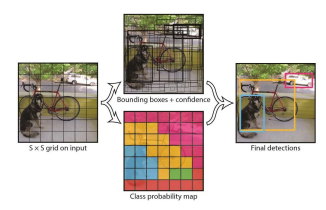
1-Stage Detector
💠 객체 영역 검출과 객체 분류를 동시에 수행
💠 2-Stage Detector보다 정확도가 낮지만, 속도가 빠름
💠 YOLO(You Only Look Once)
🔸고정된 크기의 Grid cell 로 분할
🔸각 Grid cell에서 CNN을 통해 객체 영역 검출과 분류를 수행 후 통합
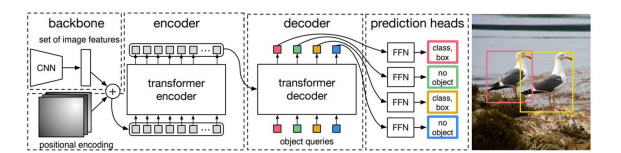
💠DETR(Detection with Transformer)
🔸CNN을 통해 검출된 특징에서 Transformer를 통해 다수 객체를 한 번에 검출
*J. Redmon et al., “You Only Look Once: Unified, Real-Time Object Detection,” Proceeding of CVPR, 2016.
**N. Carion et al., “End-to-End Object Detection with Transformers (DETR),” Proceeding of ECCV, 2020.
초해상화
💠초해상화란?
- 고해상도 영상으로 변환하는 것
💠 기존 초해상화 방법
- 보간법이나 선형 매핑을 통한 변환
- 복잡한 디테일의 변환 부정확
💠딥러닝을 통한 초해상화 방법
- 딥러닝을 통해 저-고해상도 영상 간 관계 예측
- 복잡한 디테일의 변환도 정확
